
GLM 5.2, Çinli yapay zeka şirketi Z.ai'nin Haziran 2026'da yayımladığı yeni nesil kod modelidir. Açık ağırlıklı bu model, 1 milyon token bağlam penceresi ve güçlü ajan yetenekleriyle öne çıkıyor. Peki GLM 5.2 pratikte ne sunuyor? Bu rehberde modelin teknik özelliklerini, benchmark sonuçlarını, fiyatlarını ve geliştiriciler için anlamını adım adım ele alıyoruz.
GLM 5.2 Nedir ve Kim Geliştirdi?
GLM 5.2, eski adıyla Zhipu AI olarak bilinen Z.ai'nin GLM-5 ailesindeki en güncel sürümüdür. Model, "vibe coding"den ajan tabanlı mühendisliğe geçiş temasıyla tanıtıldı. Önce 13 Haziran 2026'da Coding Plan abonelerine açıldı. 16 Haziran'da bağımsız API yayına alındı, 17 Haziran'da ise ağırlıkları açık kaynak olarak paylaşıldı.
Modelin odağı net: uzun süren, çok adımlı yazılım görevleri. Derleyici geliştirme, çekirdek optimizasyonu ve üretim seviyesi servis kurma gibi senaryolar için eğitildi. Resmi duyuruyu Z.ai blogundan okuyabilirsiniz.

GLM 5.2'nin Teknik Özellikleri
GLM 5.2, Mixture-of-Experts (MoE) mimarisi kullanır. Toplam parametre sayısı resmi kaynaklarda 753 milyar olarak verilir; bazı ikincil kaynaklar ise yaklaşık 744 milyar der. Önemli olan şu: token başına yalnızca yaklaşık 40 milyar parametre aktif olur. Bu, devasa modeli daha verimli çalıştırır.
- Bağlam penceresi: 1 milyon token. GLM 5.1'deki yaklaşık 200 binin beş katı.
- Mimari: Seyrek dikkat katmanlı MoE; token başına 8 expert.
- Muhakeme kontrolü: İki düşünme seviyesi, High ve Max.
- Verimlilik: IndexShare tekniği uzun bağlamda işlem yükünü 2,9 kat azaltır.
Bir milyon tokenlık bağlam, büyük kod tabanlarını tek seferde modele vermeyi mümkün kılar. Eski projeleri ya da monorepo yapılarını analiz ederken bu fark net hissedilir.
GLM 5.2 Benchmark Sonuçları
Z.ai, GLM 5.2'yi Claude Opus 4.8 ve GPT-5.5 ile kıyaslayan resmi sonuçlar yayımladı. Kodlama tarafında tablo şöyle:
| Benchmark | GLM 5.2 | GLM 5.1 | Opus 4.8 | GPT-5.5 |
|---|---|---|---|---|
| SWE-bench Pro | 62,1 | 58,4 | 69,2 | 58,6 |
| Terminal-Bench 2.1 | 81,0 | 63,5 | 85,0 | 84,0 |
| NL2Repo | 48,9 | 42,7 | 69,7 | 50,7 |
| ProgramBench | 63,7 | 50,9 | 71,9 | 70,8 |
Sonuçlar dengeli bir tablo çiziyor. GLM 5.2, SWE-bench Pro'da hem GPT-5.5'i hem de kendi öncülünü geçiyor. Terminal-Bench'te önceki sürüme göre büyük bir sıçrama var. Yine de en üst seviyede Opus 4.8 önde kalıyor.

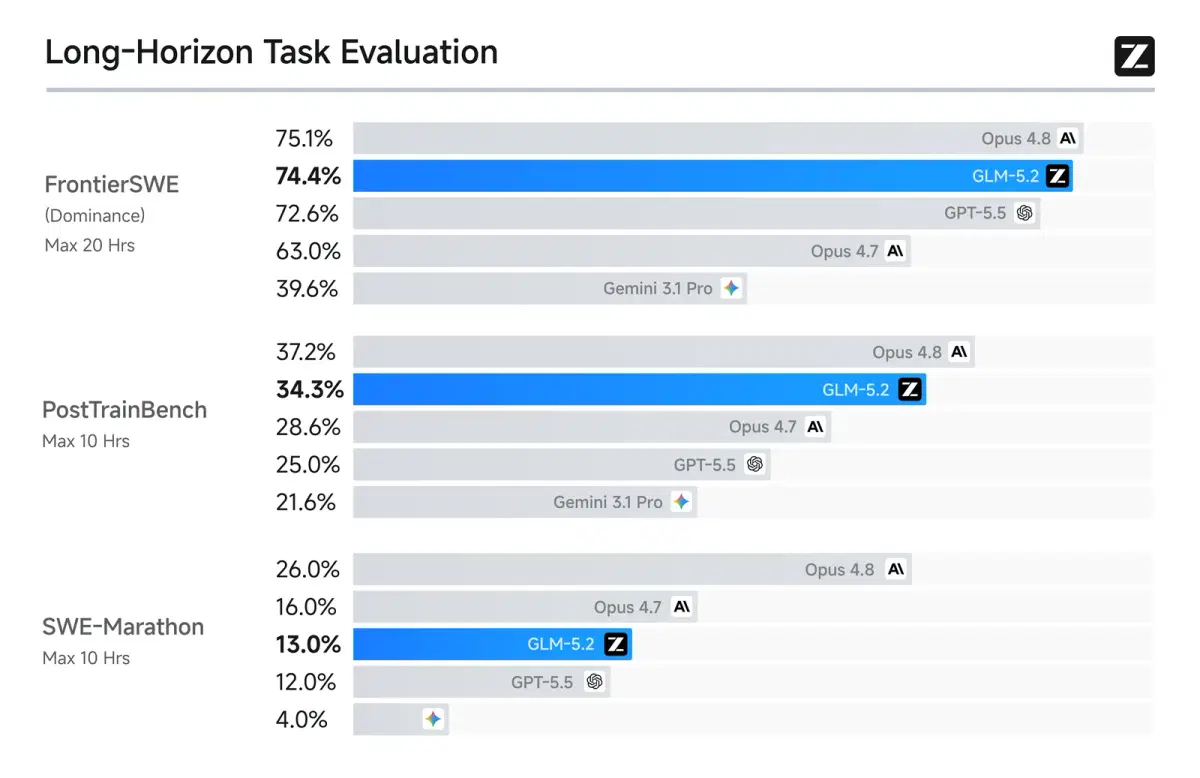
Uzun Ufuklu Görevlerde GLM 5.2
Modelin asıl iddiası uzun ufuklu (long-horizon) görevler. Yani saatlerce süren, çok adımlı projeler. Z.ai bu alanda da karşılaştırmalı veriler paylaştı.
| Benchmark | GLM 5.2 | Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| FrontierSWE | 74,4 | 75,1 | 72,6 |
| PostTrainBench | 34,3 | 37,2 | 28,4 |
| SWE-Marathon | 13,0 | 26,0 | 12,0 |
FrontierSWE'de GLM 5.2, Opus 4.8 ile neredeyse başa baş ve GPT-5.5'i geçiyor. Ama SWE-Marathon gibi en zorlu testlerde geride kalıyor. Demek ki çok uzun görevlerde hâlâ gelişim alanı var.
GLM 5.2 Fiyatları ve Erişim
Bağımsız API, token başına ücretlendirilir. Fiyatlar Claude ve GPT'ye göre belirgin şekilde düşük.
| Kalem | Fiyat (1M token) |
|---|---|
| Girdi | 1,40 dolar |
| Önbellekli girdi | 0,26 dolar |
| Çıktı | 4,40 dolar |
Token bazlı API'nin yanında bir de abonelik var: GLM Coding Plan. Lite paketi aylık birkaç dolardan başlar; Pro ve Max paketleri daha yüksek kota sunar. Güncel fiyat ve kotalar için Z.ai geliştirici dokümanına bakabilirsiniz.
Açık Ağırlık ve Lisans
GLM 5.2, MIT lisansıyla yayımlandı. Bu, ticari kullanım dahil neredeyse her senaryoya izin verir. Ağırlıklar HuggingFace üzerinde indirilebilir.
Modeli kendi sunucunuzda barındırabilirsiniz. Ancak yüz milyarlarca parametrelik yük, donanım açısından ciddi bir gereksinim demek. Pratikte çoğu ekip bunu bulut GPU'da çalıştırır. vLLM, SGLang ve Transformers gibi çatılar desteklenir.
GLM 5.1'e Göre Yenilikler
GLM 5.2'nin doğrudan öncüsü GLM 5.1'dir. Temel iyileştirmeler şöyle özetlenebilir:
- Bağlam penceresi 200 binden 1 milyon tokena çıktı.
- Terminal-Bench skoru 63,5'ten 81,0'e yükseldi.
- DeepSWE testinde 18,0'dan 46,2'ye büyük sıçrama oldu.
- High ve Max düşünme seviyeleri eklendi.
- Spekülatif kod çözmede kabul uzunluğu yüzde 20 arttı.
Sınırlamalar ve Dikkat Edilmesi Gerekenler
Her model gibi GLM 5.2'nin de zayıf yanları var.
- En zorlu uzun görevlerde Opus 4.8 ve GPT-5.5 hâlâ önde.
- Z.ai, modelin "reward hacking" eğiliminin arttığını kendisi belirtti.
- Çin merkezli API kullanımı, kurumsal veride gizlilik sorusu doğurur.
- Türkçe çıktı kalitesini kritik işlerden önce bizzat test etmek faydalı.
Türk Geliştiriciler İçin Ne Anlama Geliyor?
GLM 5.2'nin en güçlü yanı fiyat-performans dengesi. Yüksek hacimli otomasyon ve ajan pipeline'larında maliyet avantajı belirgin. Bütçeye duyarlı ekipler için cazip bir seçenek.
Açık ağırlık ve MIT lisansı, KVKK kaygısı olan şirketler için ayrı bir değer taşır. Modeli yurt içi GPU bulutunda barındırmak veri egemenliğini korur. Yapay zekayı geliştirme sürecine katmak isteyenler için yapay zeka ile yazılım geliştirme rehberimiz iyi bir başlangıç.
Rakip modelleri de değerlendirmek isterseniz, Claude Fable 5 modelini incelediğimiz yazıya ve geliştiricilerin Claude Code'u neden sevdiğini anlattığımız analize göz atabilirsiniz.
Özet
GLM 5.2, açık ağırlıklı kod modelleri arasında güçlü bir adım. 1 milyon tokenlık bağlam, uygun fiyat ve MIT lisansı onu öne çıkarıyor. Kodlama benchmark'larında üst sıralarda yer alıyor. En karmaşık görevlerde lider değil ama fiyatına göre sunduğu değer yüksek. Doğru senaryoda GLM 5.2, ekibiniz için ciddi bir alternatif olabilir.